Why can’t I use ChatGPT for everything?
Sponsored by Citrine Informatics
Large language models (LLMs) are great for some tasks – but they are not that useful when the datasets they use to function are small, and intellectual property (IP) is precious as is the case in materials and chemicals product development. Fortunately, LLMs are not the only AI solution available. Chemically aware Machine Learning SaaS platforms such as that developed by Citrine Informatics are being successfully used by leading companies to accelerate product development.
Since ChatGPT burst onto the scene in November 2022, the public’s mental image of AI has shifted from Terminator-style robots to helpful, if somewhat hallucinatory, chatbots. Large language models are now being widely adopted in business, making AI assistants commonplace. Many executives are now wondering, can we just ChatGPT everything? While LLMs are great at regurgitating existing information in a new format, or making sure this article follows grammatical convention, they have weaknesses that mean that they aren’t suitable for truly innovative development of physical and chemical products.
Here is why it won’t work.
The data isn’t good enough, or large enough
To make a large language model you need billions of textual datapoints. While many attempts have been made to scrape numerical data from scientific journals and create large databases, the quality and relevance of the data is usually not good enough to train an LLM model. Companies usually work on either reformulating an existing chemical product or developing something new and cutting-edge, and the recipes for these products are typically confidential IP. You won’t find data about them in public scientific journals.
Public data sources such as scientific journals and patents also introduce bias. Only, successful tests with high-performing materials and chemicals get put into papers. AI however, needs examples of both successful and unsuccessful tests. If it is trained only on data from successful experiments, it will think that all experiments are successful!

The peer review system also does not ensure all the data in scientific papers are accurate and sufficiently detailed such that you could be sure that you are comparing apples with apples. If you want to pool together data from separate papers, you need to know that materials were tested using the same methodology, and in the same conditions. Sadly, too many papers leave out the crucial information that would make this possible.
The best data is your own data
The best source of data for materials and chemicals is your own lab. When each datapoint is a result of an experiment that takes hours, your dataset will be small. Most projects on the Citrine Platform (the leading platform for materials and chemicals AI) begin with 40 to 60 datapoints.
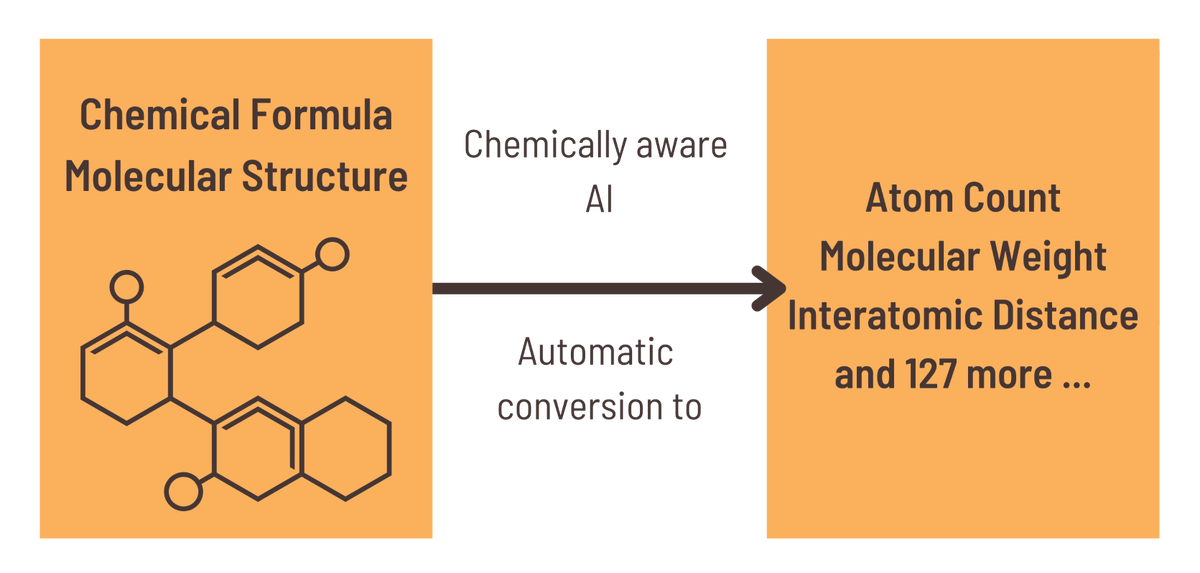
This information is then supplemented by picking the brains of product experts, who add their own domain knowledge to ensure the AI doesn’t have to relearn the laws of physics, and by the automatic generation of further data from physical models by the AI platform. The Citrine Platform understands molecular structure and chemical formulae and can calculate over 100 properties of interest such as molecular weight or average electronegativity automatically. In this way, machine learning can leverage small datasets and still accelerate product development by a factor of two or three.
Why LLMs will lead you astray
LLMs remix existing information. While that is useful when trying to write your blog article, it will fall short if you ask it to come up with a completely novel, patentable innovation. LLMs also present everything as the truth, with no nuanced calculation of uncertainty to their answers, which is key when venturing into new territories beyond your current understanding.
Sequential learning using machine learning models, on the other hand, is an iterative process that helps product experts explore solutions in a far more efficient manner – and one that’s more likely to produce results. Citrine typically sees a 50-80 percent reduction in the number of experiments needed to hit product development goals compared with a trial-and-error approach. The fundamental reason this works is because machine learning platforms not only predict properties but also, unlike an LLM, estimate how certain those predictions are. When you go to the lab to test a possible solution, you know if it is a safe bet, or a punt. You can be more strategic in your innovation pathway.
Interpretability
LLMs are also less easy to learn from. They can’t explain why they came up with what they have produced. That means product experts won’t be able to use them to gain insight into the underlying factors affecting your target properties. If an LLM hallucinates, you won’t know why, so won’t be able to fix it.

ML is a better bet
The best machine learning platforms calculate feature importance and make explicit which factors are influencing a model’s predictions, by how much and in which direction. Most of the time, a product expert will review feature importance to check that the AI model is on the right track. Occasionally, an unexpectedly important factor will appear, prompting excited exploration in a new design direction.
In summary, you can’t use LLMs for everything because, for many applications, they are a round peg in a square hole. Better tools are available for AI for science. Companies such as Citrine Informatics have spent a decade overcoming the challenge of small, sparse datasets ubiquitous in materials and chemicals R&D applications by leveraging the knowledge of product experts and making a user-friendly, chemically-aware AI platform.
To learn more, access this three-page summary of over a decade’s worth of insights from the implementation of AI in materials, chemicals and consumer packaged goods (CPG) companies.
Request a demo today—click here to get started!
by Hannah Melia, Head of Marketing, Citrine Informatics

Business Reporter Team






Most Viewed
Winston House, 3rd Floor, Units 306-309, 2-4 Dollis Park, London, N3 1HF
23-29 Hendon Lane, London, N3 1RT
020 8349 4363
© 2025, Lyonsdown Limited. Business Reporter® is a registered trademark of Lyonsdown Ltd. VAT registration number: 830519543